
端到端手语生成的渐进式变换
Ben Saunders, Necati Cihan Camgoz, and Richard Bowden
University of Surrey
{b.saunders,n.camgoz,r.bowden}@surrey.ac.uk
------------------JC 译
摘要 自动手语生成(SLP)的目的是将口语转换成在一定程度上能够媲美人工翻译的连续手语视频流。如果这是可行的,这将彻底改变聋人的交流方式。之前主要对孤立手语生成的研究工作表明更适合于全符号连续域的架构的必要性。 在这篇论文中,我们提出了渐进式变换,这是第一个以端到端的方式将分离的口语语句翻译为连续3D手语姿态序列的手语生成模型。我们引入了一个新奇的计数器解码技术,这实现了训练和推理时的连续序列生成。我们展示了两种模型的配置方案,一个直接从文本生成手语的端到端的网络,和一个利用手语注释(手语注释手语的书写表达,定义最小的词汇)的栈式网络。我们也提供了多个数据扩充过程来克服数据倾斜问题并且极大程度上提高了手语生成模型的性能。 我们为手语生成提出一种反向评估机制,在富有挑战地RWTH-PHOENIX-Weather-2014T(PHOENIX14T)数据集上展示基准量化结果并且为后续研究指定基准。代码可以在https://github.com/BenSaunders27/ProgressiveTransformersSLP
获得。
关键词: 手语生成,连续序列生成,变换,序列到序列,人体姿态生成
1 简介
手语是听障人群的一种交流语言,是一种语法结构复杂的视觉丰富的语言。因为这是他们的母语,相比于口语的书面形式,大多数聋人倾向于使用授予作为他们交流的媒介。因此,手语生成(SLP),将口语转换成连续的手语序列,让聋人参与到更广泛的、以口语为主的世界是至关重要的。之前的研究局限于连接起来的孤立的手语的生成 [ 53, 64 ],强调了改进架构以恰当地解决连续性手语的全部问题。
在该论文中,我们提出了渐进式变换,这是第一个以端到端方式将文本翻译为连续3D手语姿态序列的手语
 生成模型。我们的创新点包括用于连续变量解码的变换的一个可替代公式,其中没有预定义的词汇表。我们引入了一种计数器解码技术,通过追踪生成过程来预测连续序列的遍历变量长度,即叫做渐进式变换。这种方法还可以在推理时驱动时间、生成稳定的手语姿态输出。
生成模型。我们的创新点包括用于连续变量解码的变换的一个可替代公式,其中没有预定义的词汇表。我们引入了一种计数器解码技术,通过追踪生成过程来预测连续序列的遍历变量长度,即叫做渐进式变换。这种方法还可以在推理时驱动时间、生成稳定的手语姿态输出。
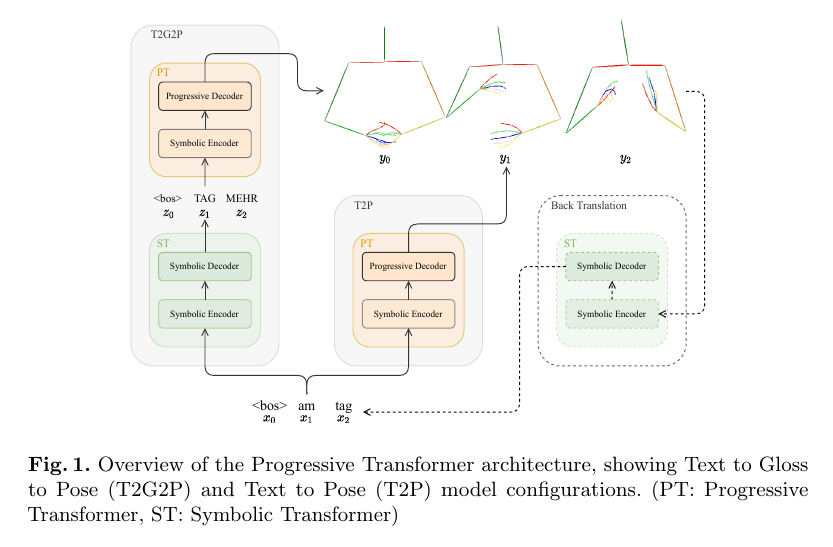
这种方法的总览如图一所示。我们评价两种不同的模型配置,第一种经过手语注释(手语注释手语的书写表达,定义最小的词汇)媒介(T2G2P)将口语翻译为手语姿态,因为这被证明可以提高翻译性能。第二种配置很直接,将口语端到端地翻译为手语(T2P)。
为了评价性能,我们为手语生成提出一种反向翻译评价方法,使用手语翻译模型翻译回口语(图一中的虚线)。我们在富有挑战性的RWTH-PHOENIX-Weather-2014T (PHOENIX14T) 数据集上进行评价,展示几种基准结果以支持后续研究。我们也给读者分享量化结果以深入了解模型的性能,生成准确的不可见文本序列的手语姿态序列。
论文剩下的内容组织如下:在第二部分,我们回顾手语翻译(SLT)和手语生成(SLP)方面的相关研究。在第三部分,我们介绍我们的渐进式翻译器手语生成模型。第四部分列出了评价协议并展示量化结果,与此同时第五部分陈列出量化案例。最后,在第六部分通过讨论我们的发现和后续可能的研究工作来总结这篇论文。
2 相关工作
手语识别和翻译:30多年前手语就成为计算机视觉研究者地焦点[4,52,57],最初研究孤立的手语识别(SLR)[46, 56],近年来研究连续手语识别(CSLR)地更高难度地任务[33,6]。然而,大多数的工作依赖于手动的特征表示[11]和统计时序模型[60)。像RWTH-PHOENIX-Weather-2014 (PHOENIX14) [17] 样更大的数据集的获得使得像卷积神经网络(CNNs)[32,34,36] 和循环神经网络(RNNs)[12,35]得以应用。
不同于手语识别,近来Camgoz等人[7]引入手语翻译的任务,旨在将手语视频直接翻译为口语语句[15,31,45,62]。由于手语和口语语法的差异,手语翻译比连续手语识别更具有挑战性。基于变换的模型是当前手语翻译领域的最先进的,共同学习识别和翻译任务[8]。
手语生成:先前的工作广泛使用动画角色,这能够生成逼真的手语,但那是依赖于短语查找和预生成的序列。统计机器翻译(SMT)已经应用于手语生成,依赖于编码困难的基于规则的静态过程。
近来,深度学习方法被应用于手语生成。Stoll等人展示了一个最初的手语生成模型,该模型结合了了神经机器翻译(NMT)和生成对抗网络(GANs)。这些作者将该问题分为三个独立训练的独立的过程,生成了一种通过查表从手语注释映射的孤立的2D骨骼姿态的连接体。相比于Stoll等人,我们的论文关注于自动手语生成和学习文本和骨骼姿态序列之间的直接映射,而不是提供一个先验。
和本篇论文最相近的是Zelinka等人的工作,他们构建一种在文本和生成的骨骼姿态之间的基于神经网络的翻译器。这些作者为原单词生成了一种7帧的单一手语,生成了固定长度和顺序的序列。比较而言,我们的模型允许动态长度的输出手语序列,从数据集中学习正确的长度和顺序,同时使用计数器解码来判断序列生成的中止。不同于那些使用专用数据集的人,我们使用公开的PHOENIX14T来生成结果,为后续手语生成研究提供基准。
神经网络翻译:神经网络翻译只在学习一种语言序列的映射,从另一种语言的源序列中生成一个目标序列。随着Kalchbrener等人引入迭代应用于隐式状态计算的单一的循环神经网络,循环神经网络第一次被提出用于解决序列到序列的问题。后来后续模型被建立,引入了编码-解码架构,将两种序列映射到一个中间嵌入空间。Bahdanau等人通过添加一种注意力机制,该注意力机制促进源序列上的软搜索以找到对目标单词预测对有用的上下文,解决了瓶颈问题。
transformer网络,一个近期神经机器翻译的突破,仅基于注意力机制,生成了一个带有全局依赖的整个源序列的表示。多头注意力机制(MHA)用于建模不同权重的输入序列的结合体,提高模型的表示能力。transformer在很多经典的自然语言处理任务,像语言建模、语句表示和包括图像自然语言描述、动作识别在内的其他领域取得了令人印象深刻的结果。与该任务相关,transformer网络之前已经被应用于连续输出任务,像语音合成、音乐生成和图像生成。
将神经机器翻译方法应用于连续输出任务是一个相对较少研究的问题。编码-解码模型和循环神经网络已经被用于将文本映射为人类动作序列,与此同时,对抗判别器能够生成逼真的姿态。为了判断连续输出序列的长度,之前的工作使用了固定的输出规格,这限制了模型的灵活性,现在使用二进制序列结束(EOS)标志或者一个序列结束令牌的连续表示。
3 渐进式变换
| 在这个部分,我们介绍渐进式变换,一种学习去将口语序列翻译为连续手语姿态序列的手语生成模型。我们的目标是,给定一个有T个词的口语序列$X = (X_1,···,X_T)$, 学习生成有U时间步的手语序列$Y=(y_1,···,y_U)$的条件概率$p(Y | X)$. 手语注释可用作中介监督网络,公式为$Z = (Z_1,···,Z_N)$,其中由N个手语注释,现在目标就是学习条件概率$p(Z | X)$和$p(Y | Z)$。 |
从参考文本序列生成目标手语序列带来一些挑战。首先,序列长度有极大的差异,帧的数量远大于词的数量(U »T)。因为手语和口语由不同的词汇和语法,序列也有着非单一的关系。最后,目标手语占据了一个连续的向量空间,需要文本的离散空间的不同表示。
为了解决连续手语序列生成问题,我们提出一种渐进式变幻的架构,它允许从一个符号翻译为一个连续的序列域。我们首先将符号变换架构形式化,将输入转换为目标符号特征空间,细节如图2a所示。这被用于我们的文本到注释到姿态(T2G2P)模型将口语转换为注释表示作为姿态生成钱的中间步骤,如图1。
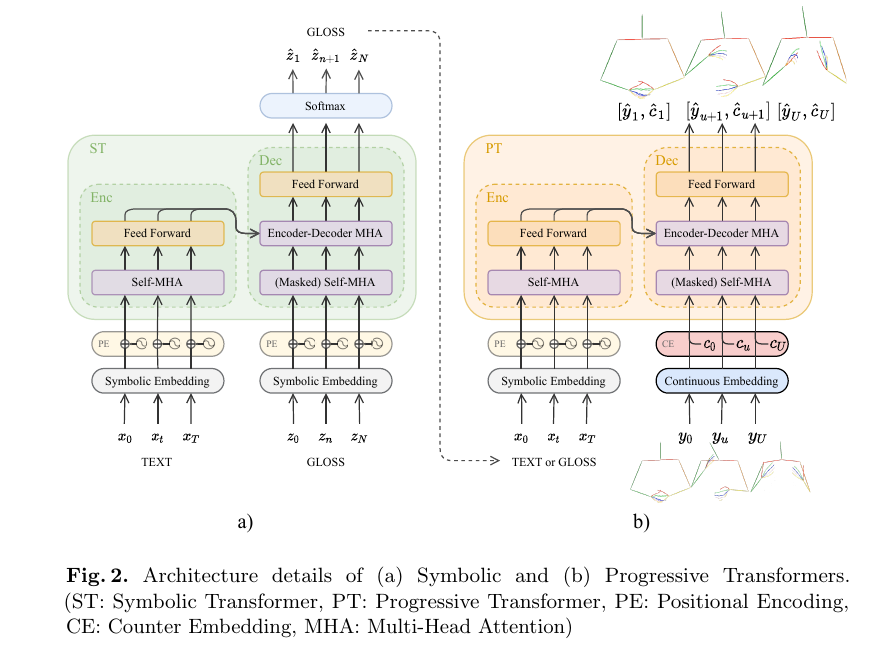
接着我们描述渐进式转换架构,将一个符号输入转换为连续输出表示,如图2b所示。我们使用这个模型来生成逼真、容易理解的手语序列,而不是通过T2G2P模型中的注释监督或通过我们的端到端的文本到姿态(T2P)模型直接从口语得到。为了能够预测连续输出的序列长度,我们引入一个计数器解码,它允许模型跟中序列产生过程。在这一节的剩余部分,我们详细讨论架构的每个部分。
3.1 符号变换
我们构建在经典的变换基础上,一个模型设计用来学习符号源与目标语言的映射。在这个工作中,符号变换(图2a)将源文本翻译为目标注释序列。按照标准的NMT管道,我们首先输入源序列, $x_t$, 接着目标序列$z_t$, 经过线性嵌入层的令牌,来表示更高维度空间的one-hot-vector, 更高维空间里具有相似含义的令牌更相近。符号嵌入,其中权重W,偏移量b,可以用公式表示为: \(w_t = W^x·x_t+b^x, g_n = W^z·z_n+b^z \tag 1\) 其中$w_t和g_n$是源序列和目标序列的令牌。
变换网络没有词序的概念,因为所有的源令牌被同时输入网络且不带位置信息。为了弥补这个并加入时序,我们在每个输入嵌入后加入了一个时序嵌入层。对于符号变换,我们应用了位置编码,如: \(\hat w_t = w_t + PositionalEncoding(t) \tag 2\\\)
\[\hat g_n = g_n + PositionalEncoding(n) \tag 3\]其中PositionalEncoding是以相对序列位置t或n为参数的预定义正弦函数。
我们的符号变换模型由编码器-解码器架构构成。编码器首先通过自注意机制学习源序列的上下文表示,理解每个输入令牌与整个序列的关系。接着解码器判断源序列与目标序列的映射关系,校准子空间表示并且以一种自动回归的方式生成目标预测。
1. Ahn, H., Ha, T., Choi, Y., Yoo, H., Oh, S.: Text2Action: Generative Adversarial Synthesis from Language to Action. In: International Conference on Robotics and Automation (ICRA) (2018)
2. Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer Normalization. arXiv preprint arXiv:1607.06450 (2016)
3. Bahdanau, D., Cho, K., Bengio, Y.: Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473 (2014)
4. Bauer, B., Hienz, H., Kraiss, K.F.: Video-Based Continuous Sign Language Recog- nition using Statistical Methods. In: Proceedings of 15th International Conference on Pattern Recognition (ICPR) (2000)
5. Berndt, D.J., Clifford, J.: Using Dynamic Time Warping to Find Patterns in Time Series. In: AAA1 Workshop on Knowledge Discovery in Databases (KDD) (1994)
6. Camgoz, N.C., Hadfield, S., Koller, O., Bowden, R.: SubUNets: End-to-end Hand Shape and Continuous Sign Language Recognition. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2017)
7. Camgoz, N.C., Hadfield, S., Koller, O., Ney, H., Bowden, R.: Neural Sign Language Translation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
8. Camgoz, N.C., Koller, O., Hadfield, S., Bowden, R.: Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
9. Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: OpenPose: Realtime Multi- Person 2D Pose Estimation using Part Affinity Fields. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
10. Cho, K., van Merriënboer, B., Bahdanau, D., Bengio, Y.: On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In: Proceedings of the Syntax, Semantics and Structure in Statistical Translation (SSST) (2014)
11. Cooper, H., Ong, E.J., Pugeault, N., Bowden, R.: Sign Language Recognition using Sub-units. Journal of Machine Learning Research (JMLR) 13 (2012)
12. Cui, R., Liu, H., Zhang, C.: Recurrent Convolutional Neural Networks for Contin- uous Sign Language Recognition by Staged Optimization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
12. Cui, R., Liu, H., Zhang, C.: Recurrent Convolutional Neural Networks for Contin- uous Sign Language Recognition by Staged Optimization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
13. Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q.V., Salakhutdinov, R.: Transformer- XL: Attentive Language Models Beyond a Fixed-Length Context. In: International Conference on Learning Representations (ICLR) (2019)
14. Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics (ACL) (2018)
15. Duarte, A.C.: Cross-modal Neural Sign Language Translation. In: Proceedings of the ACM International Conference on Multimedia (ICME) (2019)
16. Ebling, S., Camgöz, N.C., Braem, P.B., Tissi, K., Sidler-Miserez, S., Stoll, S., Hadfield, S., Haug, T., Bowden, R., Tornay, S., et al.: SMILE: Swiss German Sign Language Dataset. In: Proceedings of the International Conference on Language Resources and Evaluation (LREC) (2018)
17. Forster, J., Schmidt, C., Koller, O., Bellgardt, M., Ney, H.: Extensions of the Sign Language Recognition and Translation Corpus RWTH-PHOENIX-Weather. In: Proceedings of the International Conference on Language Resources and Evaluation (LREC) (2014)
18. Ginosar, S., Bar, A., Kohavi, G., Chan, C., Owens, A., Malik, J.: Learning Individual Styles of Conversational Gesture. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
19. Girdhar, R., Carreira, J., Doersch, C., Zisserman, A.: Video Action Transformer Network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
20. Glauert, J., Elliott, R., Cox, S., Tryggvason, J., Sheard, M.: VANESSA: A System for Communication between Deaf and Hearing People. Technology and Disability (2006)
21. Glorot, X., Bengio, Y.: Understanding the Difficulty of Training Deep Feedforward Neural Networks. In: Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) (2010)
22. Graves, A.: Generating Sequences With Recurrent Neural Networks. arXiv preprint arXiv:1308.0850 (2013)
23. He, K., Zhang, X., Ren, S., Sun, J.: Deep Residual Learning for Image Recogni- tion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
24. Huang, C.Z.A., Vaswani, A., Uszkoreit, J., Shazeer, N., Simon, I., Hawthorne, C., Dai, A.M., Hoffman, M.D., Dinculescu, M., Eck, D.: Music Transformer. In: International Conference on Learning Representations (ICLR) (2018)
25. Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-Image Translation with Condi- tional Adversarial Networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
26. Kalchbrenner, N., Blunsom, P.: Recurrent Continuous Translation Models. In: Pro- ceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (2013)
27. Karpouzis, K., Caridakis, G., Fotinea, S.E., Efthimiou, E.: Educational Resources and Implementation of a Greek Sign Language Synthesis Architecture. Computers & Education (CAEO) (2007)
28. Kayahan, D., Güngör, T.: A Hybrid Translation System from Turkish Spoken Lan- guage to Turkish Sign Language. In: IEEE International Symposium on INnovations in Intelligent SysTems and Applications (INISTA) (2019)
29. Kingma, D.P., Ba, J.: Adam: A Method for Stochastic Optimization. In: Proceedings of the International Conference on Learning Representations (ICLR) (2014)
30. Kipp, M., Heloir, A., Nguyen, Q.: Sign Language Avatars: Animation and com- prehensibility. In: International Workshop on Intelligent Virtual Agents (IVA) (2011)
31. Ko, S.K., Kim, C.J., Jung, H., Cho, C.: Neural Sign Language Translation based on Human Keypoint Estimation. Applied Sciences (2019)
32. Koller, O., Camgoz, N.C., Bowden, R., Ney, H.: Weakly Supervised Learning with Multi-Stream CNN-LSTM-HMMs to Discover Sequential Parallelism in Sign Language Videos. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2019)
33. Koller, O., Forster, J., Ney, H.: Continuous Sign Language Recognition: Towards Large Vocabulary Statistical Recognition Systems Handling Multiple Signers. Com- puter Vision and Image Understanding (CVIU) (2015)
34. Koller, O., Ney, H., Bowden, R.: Deep Hand: How to Train a CNN on 1 Million Hand Images When Your Data Is Continuous and Weakly Labelled. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
35. Koller, O., Zargaran, S., Ney, H.: Re-Sign: Re-Aligned End-to-End Sequence Mod- elling with Deep Recurrent CNN-HMMs. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
36. Koller, O., Zargaran, S., Ney, H., Bowden, R.: Deep Sign: Hybrid CNN-HMM for Continuous Sign Language Recognition. In: Proceedings of the British Machine Vision Conference (BMVC) (2016)
37. Kouremenos, D., Ntalianis, K.S., Siolas, G., Stafylopatis, A.: Statistical Machine Translation for Greek to Greek Sign Language Using Parallel Corpora Produced via Rule-Based Machine Translation. In: IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI) (2018)
38. Kreutzer, J., Bastings, J., Riezler, S.: Joey NMT: A Minimalist NMT Toolkit for Novices. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (2019)
39. Lee, H.Y., Yang, X., Liu, M.Y., Wang, T.C., Lu, Y.D., Yang, M.H., Kautz, J.: Dancing to Music. In: Advances in Neural Information Processing Systems (NIPS) (2019)
40. Li, G., Zhu, L., Liu, P., Yang, Y.: Entangled Transformer for Image Captioning. In: Proceedings of the IEEE International Conference on Computer Vision (CVPR) (2019)
41. Li, N., Liu, S., Liu, Y., Zhao, S., Liu, M.: Neural Speech Synthesis with Transformer Network. In: Proceedings of the AAAI Conference on Artificial Intelligence (2019)
42. McDonald, J., Wolfe, R., Schnepp, J., Hochgesang, J., Jamrozik, D.G., Stumbo, M., Berke, L., Bialek, M., Thomas, F.: Automated Technique for Real-Time Pro- duction of Lifelike Animations of American Sign Language. Universal Access in the Information Society (UAIS) (2016)
43. Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed Represen- tations of Words and Phrases and their Compositionality. In: Advances in Neural Information Processing Systems (NIPS) (2013)
44. Mukherjee, S., Ghosh, S., Ghosh, S., Kumar, P., Roy, P.P.: Predicting Video- frames Using Encoder-convlstm Combination. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2019)
45. Orbay, A., Akarun, L.: Neural Sign Language Translation by Learning Tokenization. arXiv preprint arXiv:2002.00479 (2020)
46. Özdemir, O., Camgöz, N.C., Akarun, L.: Isolated Sign Language Recognition using Improved Dense Trajectories. In: Proceedings of the Signal Processing and Communication Application Conference (SIU) (2016)
47. Parmar, N., Vaswani, A., Uszkoreit, J., Kaiser, L., Shazeer, N., Ku, A., Tran, D.: Image Transformer. In: International Conference on Machine Learning (ICML) (2018)
48. Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., Lerer, A.: Automatic Differentiation in PyTorch. In: NIPS Autodiff Workshop (2017)
49. Plappert, M., Mandery, C., Asfour, T.: Learning a Bidirectional Mapping between Human Whole-Body Motion and Natural Language using Deep Recurrent Neural Networks. Robotics and Autonomous Systems (2018)
50. Ren, Y., Ruan, Y., Tan, X., Qin, T., Zhao, S., Zhao, Z., Liu, T.Y.: FastSpeech: Fast, Robust and Controllable Text to Speech. In: Advances in Neural Information Processing Systems (NIPS) (2019)
51. Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X.: Improved Techniques for Training GANs. In: Advances in Neural Information Processing Systems (NIPS) (2016)
52. Starner, T., Pentland, A.: Real-time American Sign Language Recognition from Video using Hidden Markov Models. Motion-Based Recognition (1997)
53. Stoll, S., Camgoz, N.C., Hadfield, S., Bowden, R.: Sign Language Production using Neural Machine Translation and Generative Adversarial Networks. In: Proceedings of the British Machine Vision Conference (BMVC) (2018)
54. Stoll, S., Camgoz, N.C., Hadfield, S., Bowden, R.: Text2Sign: Towards Sign Language Production using Neural Machine Translation and Generative Adversarial Networks. International Journal of Computer Vision (IJCV) (2020)
55. Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to Sequence Learning with Neural Networks. In: Proceedings of the Advances in Neural Information Processing Systems (NIPS) (2014)
56. Süzgün, M., Özdemir, H., Camgöz, N., Kındıroğlu, A., Başaran, D., Togay, C., Akarun, L.: Hospisign: An Interactive Sign Language Platform for Hearing Impaired. Journal of Naval Sciences and Engineering (JNSE) (2015)
57. Tamura, S., Kawasaki, S.: Recognition of Sign Language Motion Images. Pattern Recognition (1988)
58. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention Is All You Need. In: Advances in Neural Information Processing Systems (NIPS) (2017)
59. Vila, L.C., Escolano, C., Fonollosa, J.A., Costa-jussà, M.R.: End-to-End Speech Translation with the Transformer. In: Advances in Speech and Language Technolo- gies for Iberian Languages (IberSPEECH) (2018)
60. Vogler, C., Metaxas, D.: Parallel Midden Markov Models for American Sign Lan- guage Recognition. In: Proceedings of the IEEE International Conference on Com- puter Vision (ICCV) (1999)
61. Xiao, Q., Qin, M., Yin, Y.: Skeleton-based Chinese Sign Language Recognition and Generation for Bidirectional Communication between Deaf and Hearing People. In: Neural Networks (2020)
62. Yin, K.: Sign Language Translation with Transformers. arXiv preprint arXiv:2004.00588 (2020)
63. Zelinka, J., Kanis, J.: Neural Sign Language Synthesis: Words Are Our Glosses. In: The IEEE Winter Conference on Applications of Computer Vision (WACV) (2020)
64. Zelinka, J., Kanis, J., Salajka, P.: NN-Based Czech Sign Language Synthesis. In: International Conference on Speech and Computer (SPECOM) (2019)
65. Zhang, Z., Han, X., Liu, Z., Jiang, X., Sun, M., Liu, Q.: ERNIE: Enhanced Language Representation with Informative Entities. In: 57th Annual Meeting of the Association for Computational Linguistics (ACL) (2019)
66. Zhou, L., Zhou, Y., Corso, J.J., Socher, R., Xiong, C.: End-to-End Dense Video Captioning with Masked Transformer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018)
67. Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired Image-to-Image Translation us- ing Cycle-Consistent Adversarial Networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
文档信息
- 本文作者:Yang Jucai
- 本文链接:https://yangjucai.github.io//2022/05/30/Progressive-Transformers-for-End-to-End-Sign-Language-Production/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)